图1 计算机仿真
蛋白质折迭过程需要大量计算
生物信息学是结合基因蛋白质学及信息科技的新兴研究领域,其最终目标在发现新的生物认知、厘清细胞各阶段的表现,以利人们对疾病和药物使用有更精确的了解。故其现阶段执行的任务有分析核酸序列、蛋白质序列、蛋白质结构、蛋白质家族及其生化反应等。
其中,需要信息及半导体技术协助的研究包括:序列组合、序列分析、比较基因组学、计算基因遗传学、基因认定、蛋白质三维结构分析、基因微数组芯片分析、分子演化、药物设计等领域。
高性能计算设备方能应付大量运算需求
测序是基因研究的基础,目前高通量基因测序设备及配套硬软件均依赖进口,如何让此核心技术生根关系着本土相关产业的发展。而此高性能的设备多用于以下两个主要应用:
一、基因搜索及比对:将已知之 DNA 结构辨别标准输入计算器内,可判断样本序列是否存在,以及此序列与不同物种间之DNA关联性;
二、蛋白质折迭仿真及计算器辅助药物设计:利用重组或扩展已有的蛋白质是预防疾病和药物设计的关键,因此计算器图学技术与计算方法至关重要。以几何、能量与活性等三大方向来探讨如何使用最小能量原理来改进药物设计中的分子对接过程之效能、加速药物设计时程与降低研发成本是目前最迫切的课题。
为生物基因计算应用设计之 FPGA 系统
NVIDIA 的 CUDA 平台,其拥有通过 C 语言来控制 GPU 的开发环境,适合并行运算。在 CUDA 架构中,作 DNA 测序、短序列拼装,可发挥并行计算之优势,加速计算并生成三维基因图谱。
Invitrogen 和 Active Motif 两大生技公司也合作利用 FPGA 技术分析新一代的测序数据。TimeLogic 生物计算系统由一至多片的 PCI Express x 1 之 FPGA 板卡组成,其整合FPGA 加速器和基因组学算法,能将新发现的数据和已知的基因进行快速比对,处理速度等同于普通 CPU 的 100 倍以上。
在要求更高的蛋白质折迭仿真算法中,研究人员先以遗传算法来加速接合位置的几何搜寻;再以能量为重点,于实验中使用李亚普诺夫函数中的稳定理论来降低接合位置数,以便进一步增进分子对接的效能;同时使用 NURBS 曲线中的插入顶点与权重调整来加速分子系统达到最小能量状态;最后以各种不同的药物受体模型来做计算机仿真计算,利用最小能量原理,判断出接近全局能量最小区域的对接状态之稳定度,并对其各种分子活性进行评估。
为了运用 FPGA 主芯片实现计算应用分子力场,以及配合 LYAPUNOV 指数求出降低分子对接的几何位置数量与稳定度,我们提出以图2中所示之系统架构来满足更高层级研究人员所需。
如图2所示,单片系统的主要功能是将高速输入之数据,利用 4 组 GigE 网口,提供给后端 FPGA 进行序列比对处理。高硬件架构的核心部份为双 DDR2 SODIMM 模块之 Multi-Port Controller,内存的管理单元及总线设计是提升整体高速运算效能之关键。为了将序列比对时重要之 Linked List 数据结构以硬件 FPGA 实现,另外安排了特殊ZBT ( Zero Bus Turnaround ) SRAM 以储存 Pointer 之部份。使两个读写总在线的子系统可以同时平行运作而不互相干扰,进而达到动态并行处理的效能。
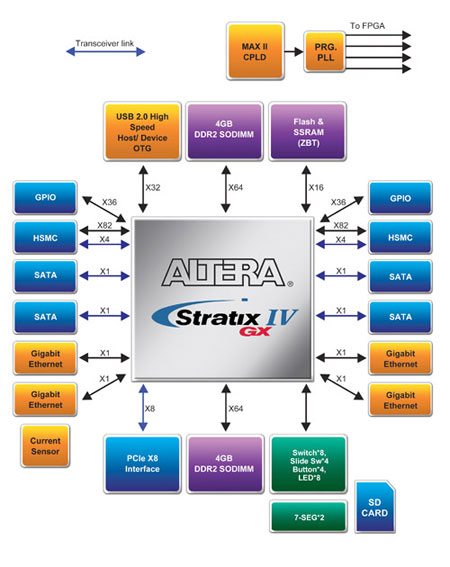
图2 生物基因及蛋白质运算 FPGA 平台架构图
由于 PC 主板以 DMA 方式收送软件处数据,为了符合要求,系统以 PCI Express x 8 提供 16Gb/s 带宽,系统并提供 2 个 HSMC 接头做为板卡互连之高速接口,而 HSMC 接头的关键带宽由 8 对能承受 10Gb/s 之高速讯号线担任。
以 HSPICE 仿真克服 10Gb/s 系统设计瓶颈
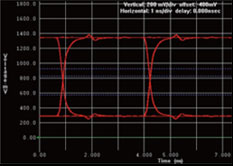
圖3 DDR2 / DDR3 之模擬結果
高速 FPGA 开发平台的讯号完整性是系统成功与否之关键。因此在设计过程中,我们运用包含 Hspice 在内的多种仿真分析工具,通过对具体问题进行分析来优化零配件选择和设计折衷,如层迭结构、介电材料、讯号线拓朴结构、线长、线宽和阻抗匹配组件等,并根据仿真结果对设计进行调整,以便在设计时间内解决大多数的讯号完整性问题。
图3为我们使用仿真分析阻抗匹配组件对DDR2地址讯号的影响,透过仿真可以看到终端匹配电阻的使用将使讯号拥有较少的 overshoot 与 undershoot。
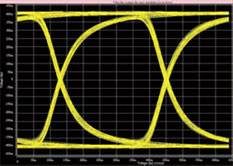
圖4 HSPICE 眼圖結果
图5为最后依据多方研究人员需求,开发完成之 FPGA 平台。目前由台湾在蛋白质折迭及药物设计方面之专家进行算法加速上之测试。
对此平台细节有兴趣之读者,请参考 de4.terasic.com
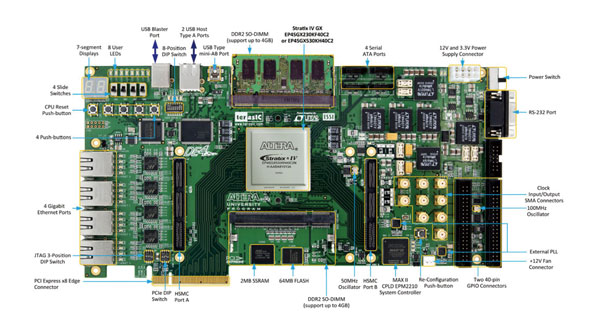
图5 FPGA 系统实际成品照片